정규 표현식
"오늘의AI위키"의 AI를 통해 더욱 풍부하고 폭넓은 지식 경험을 누리세요.
1. 개요
정규 표현식은 특정 문자열 집합을 정의하는 데 사용되는 패턴으로, 언어학, 이론 전산학의 오토마타 이론과 형식 언어 이론에서 기원한다. 1968년 켄 톰프슨에 의해 텍스트 편집기 QED에 도입된 이후, 유닉스 환경의 grep, sed, Perl 등 다양한 도구와 프로그래밍 언어에서 널리 사용된다. 정규 표현식은 데이터 검증, 스크래핑, 파싱 등 다양한 텍스트 처리 작업에 활용되며, POSIX 표준에 따라 기본 정규 표현식(BRE)과 확장 정규 표현식(ERE)으로 구분된다. 펄(Perl)은 더 풍부한 기능을 제공하며, 펄 호환 정규 표현식(PCRE)은 자바, 파이썬, 루비 등 여러 언어에서 지원된다.
더 읽어볼만한 페이지
- 오토마타 이론 - 유한 상태 기계
유한 상태 기계는 입력에 따라 상태를 바꾸는 추상적인 기계 모델로, 초기 상태, 전이 함수, 종료 상태 등으로 구성되며 결정적/비결정적 유한 오토마타로 나뉘어 다양한 분야에 활용된다. - 오토마타 이론 - 튜링 기계
튜링 기계는 앨런 튜링이 제시한 계산 모델로, 테이프 위에서 기계적으로 작동하며, 유한한 상태, 테이프, 헤드, 명령 표를 통해 작동하고, 계산 가능성과 알고리즘의 한계를 연구하는 데 사용된다. - 코드 예시에 관한 문서 - 순서도
순서도는 컴퓨터 알고리즘이나 프로세스를 시각적으로 표현하는 도구로, 흐름 공정 차트에서 기원하여 컴퓨터 프로그래밍 분야에서 알고리즘을 설명하는 데 사용되며, 다양한 종류와 소프트웨어 도구가 존재한다. - 코드 예시에 관한 문서 - 람다 대수
람다 대수는 알론조 처치가 수학기초론 연구를 위해 도입한 형식 체계로, 초기 체계의 모순 수정 후 유형 없는 람다 대수와 단순 유형 람다 대수가 발표되었으며, 프로그래밍 언어와의 관계가 명확해지면서 컴퓨터 과학과 언어학에서 중요한 위치를 차지하며 함수형 프로그래밍 언어의 기반이 되었고, 튜링 완전성을 가지는 등 다양한 분야에 응용된다.
| 정규 표현식 | |
|---|---|
| 정규 표현식 | |
 | |
| 기본 정보 | |
| 다른 이름 | 정규식 정규 묘사 정규 패턴 |
| 개요 | |
| 종류 | 형식 언어 |
| 용도 | 문자열 검색 및 조작 |
| 역사 | |
| 기원 | 1950년대, 스티븐 클레이니의 정규 집합 이론 |
| 구현 | vi, lex, sed, grep, AWK, Perl, Tcl, Python, Java, JavaScript, .NET Framework |
| 특징 | |
| 구성 요소 | 리터럴 문자 메타 문자 문자 클래스 수량자 그룹 및 캡처 역참조 앵커 대체 플래그 |
| 패턴 매칭 방법 | 백트래킹 결정적 유한 오토마타 |
| 활용 | |
| 사용 분야 | 텍스트 편집기 프로그래밍 언어 유틸리티 |
| 예시 | 이메일 주소 유효성 검사 전화 번호 형식 확인 특정 패턴의 텍스트 검색 및 대체 |
| 추가 정보 | |
| 참고 자료 | 정규 표현식 엔진 정규 표현식 문법 정규 표현식 예제 |
2. 역사
(''s''*는 0번 이상의 ''s''를 뜻함)]]
정규 표현식의 개념은 1951년 수학자 스티븐 클레이니가 '정규 이벤트'(regular event)라는 수학적 표기법을 사용하여 정규 언어를 설명하면서 시작되었다.[84][6] 이는 이론 컴퓨터 과학의 하위 분야인 오토마타 이론 및 형식 언어 이론에서 비롯되었다. 초기의 다른 패턴 매칭 구현으로는 SNOBOL 언어가 있었지만, 이는 정규 표현식을 사용하지 않고 자체적인 패턴 매칭 구문을 사용했다.
정규 표현식이 널리 사용되기 시작한 것은 1968년 켄 톰프슨이 QED 편집기에 클레이니의 표기법을 도입하여 텍스트 파일 내 패턴을 찾는 기능을 구현하면서부터이다.[8][9] 톰프슨은 속도를 높이기 위해 IBM 7094 컴퓨터에서 JIT 컴파일 방식을 사용하여 정규 표현식 매칭을 구현했는데, 이는 JIT 컴파일의 중요한 초기 사례 중 하나로 꼽힌다. 이후 그는 이 기능을 유닉스 운영체제의 기본 편집기인 ed에 추가했고, 이는 나중에 유명한 텍스트 검색 도구인 grep의 탄생으로 이어졌다. 'grep'이라는 이름은 ed 편집기에서 "정규 표현식으로 전역 검색 후 일치하는 줄 출력"(`g/re/p`)을 수행하는 명령어에서 유래했다.[10] 비슷한 시기에 더글러스 T. 로스를 포함한 연구자 그룹은 컴파일러 설계 시 어휘 분석에 사용되는 정규 표현식 기반 도구를 구현하기도 했다.
1970년대에는 벨 연구소에서 개발된 유닉스 프로그램들, 예를 들어 vi, lex, sed, AWK, expreng 등과 이맥스 같은 다른 프로그램들에서 다양한 형태의 정규 표현식이 사용되었다. 이러한 초기 정규 표현식 형식들은 1992년 POSIX.2 표준으로 제정되어 표준화되었다.
1980년대에는 펄 언어에서 더 복잡하고 강력한 정규 표현식 기능이 등장했다. 이는 헨리 스펜서가 1986년에 작성한 정규 표현식 라이브러리에서 파생된 것으로, 스펜서는 나중에 Tcl 언어를 위한 '고급 정규 표현식(Advanced Regular Expressions)' 구현을 만들기도 했다.[11] 스펜서의 Tcl 정규 표현식 라이브러리는 하이브리드 NFA/DFA 구현을 통해 성능을 개선했으며, PostgreSQL과 같은 소프트웨어 프로젝트에서 채택되었다.[12] 펄은 스펜서의 초기 라이브러리를 기반으로 많은 새로운 기능을 추가하며 발전했다.[13] 이후 라쿠(이전 명칭 펄 6) 프로젝트에서는 펄의 정규 표현식 통합을 개선하고 구문 분석 표현 문법 정의를 지원하도록 기능을 확장하여, 라쿠 규칙이라는 미니 언어를 개발했다.[14]
한편, 문서 및 데이터베이스 모델링을 위한 구조화된 정보 표준 분야에서도 정규 표현식이 활용되었다. 1960년대부터 시작되어 1980년대에 ISO SGML과 같은 산업 표준이 통합되면서 확산되었으며, DTD 요소 그룹 구문 등에서 그 예를 찾아볼 수 있다. 정규 표현식이 널리 쓰이기 전에는 많은 검색 언어에서 `*`(임의 문자열)나 `?`(단일 문자) 같은 간단한 와일드카드만 지원했는데, 파일 이름 검색에 사용되는 glob 구문이나 SQL `LIKE` 연산자 등에서 그 흔적을 볼 수 있다.
1997년에는 필립 헤이즐이 펄의 정규 표현식 기능과 매우 유사하게 작동하는 PCRE(Perl Compatible Regular Expressions) 라이브러리를 개발했다. PCRE는 PHP, 아파치 HTTP 서버 등 수많은 최신 소프트웨어에서 널리 사용되고 있다.[15]
오늘날 정규 표현식은 다양한 프로그래밍 언어(자바, 파이썬 등), 텍스트 처리 프로그램(특히 어휘 분석기), 고급 텍스트 편집기 등에서 광범위하게 지원된다. 많은 언어에서 표준 라이브러리의 일부로 제공되거나(자바, 파이썬), 언어 자체의 구문에 내장되어 있다(펄, ECMAScript). 2010년대 후반부터는 기존의 CPU 기반 구현보다 더 빠른 속도를 제공하는 하드웨어(FPGA, GPU) 기반의 PCRE 호환 정규 표현식 엔진도 등장하고 있다.[16][17]
3. 기본 개념
정규 표현식(Regular Expression), 또는 줄여서 '''regex'''는 특정 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 문자열이다. 주로 '''패턴'''(pattern)이라고 불리며, 검색하거나 변경하려는 특정 문자열 집합을 지정하기 위해 사용된다.[85][18]
정규 표현식은 기본적으로 '리터럴(literal)'이라 불리는 일반 문자와 '메타문자(metacharacter)'라 불리는 특수 문자로 구성된다.a는 단순히 문자 'a'와 일치한다.a.에서 a는 리터럴 문자 'a'를 의미하지만, .는 줄 바꿈 문자를 제외한 모든 단일 문자와 일치하는 메타문자이다. 따라서 a. 패턴은 'a' 다음에 어떤 문자 하나가 오는 문자열(예: 'ab', 'a!', 'a9' 등)과 일치한다.
메타문자와 리터럴 문자를 조합하여 단순한 문자열 일치부터 매우 복잡하고 유연한 패턴 검색까지 가능하다. 예를 들어, .는 매우 포괄적인 패턴(거의 모든 단일 문자와 일치)이고, a는 오직 'a'와만 일치하는 정확한 패턴이다.
정규 표현식은 와일드카드 문자와 유사한 기능을 하지만, 훨씬 더 다양하고 강력한 패턴 표현 능력을 제공한다. 예를 들어, 문서 편집기에서 "serialise"와 "serialize"라는 두 가지 철자를 모두 찾고 싶을 때 seriali[sz]e라는 정규 표현식을 사용할 수 있다. 여기서 [sz]는 's' 또는 'z' 중 하나와 일치하는 메타문자 표현이다. 와일드카드는 주로 파일 이름 검색 등에서 제한적으로 사용되는 반면, 정규 표현식은 복잡한 텍스트 처리 및 데이터 추출에 널리 활용된다. 예를 들어, ^[ \t]+|[ \t]+$ 패턴은 줄의 시작이나 끝에 있는 불필요한 공백 문자들을 찾아 제거하는 데 사용될 수 있다.
정규 표현식을 구성하는 주요 연산자(메타문자)는 다음과 같으며, 이들을 조합하여 복잡한 패턴을 만든다.|)을 사용하여 여러 표현 중 하나를 선택할 수 있다. (예: cat|dog)())를 사용하여 표현식의 일부를 그룹으로 묶어 연산자의 적용 범위나 우선순위를 지정한다. (예: gr(a|e)y)? (0번 또는 1번), * (0번 이상, 클레이니 스타), + (1번 이상, 클레이니 플러스) 등이 있다.. 문자는 일반적으로 줄 바꿈 문자를 제외한 모든 단일 문자와 일치한다.
이러한 기본 개념들을 바탕으로 정규 표현식은 다양한 프로그래밍 언어, 텍스트 편집기, 명령 줄 도구 등에서 강력한 문자열 처리 도구로 사용된다.
3. 1. 불리언 "또는"
수직선은 여러 항목 중 하나를 선택하기 위해 사용된다. 예를 들어, gray|grey는 "gray" 또는 "grey"와 일치한다. 이는 괄호를 이용한 그룹 묶기와 함께 사용되어 gr(a|e)y와 같이 표현될 수도 있으며, 이 역시 "gray" 또는 "grey"와 일치한다.
3. 2. 그룹 묶기
괄호는 연산자의 범위와 우선 순위를 정의하는 데 사용된다. 예를 들어, gray|grey와 gr(a|e)y는 "gray" 또는 "grey"라는 문자열 집합을 설명하는 동일한 패턴이다. gr(a|e)y에서 괄호로 묶인 (a|e) 부분은 'a' 또는 'e' 중 하나를 의미하게 되어, 전체적으로 "gray" 또는 "grey"와 일치하게 된다.
3. 3. 양의 지정
| 기호 | 설명 | 예시 |
|---|---|---|
? | 물음표는 바로 앞의 요소가 0번 또는 1번 나타나는 경우를 의미한다. | colou?r는 "color"와 "colour" 둘 다 일치시킨다. |
* | 별표는 바로 앞의 요소가 0번 이상 나타나는 경우를 의미한다. | ab*c는 "ac", "abc", "abbc", "abbbc" 등을 일치시킨다. |
+ | 덧셈 기호는 바로 앞의 요소가 1번 이상 나타나는 경우를 의미한다. | ab+c는 "abc", "abbc", "abbbc" 등을 일치시키지만 "ac"는 일치시키지 않는다. |
{n}[85][18] | 바로 앞의 요소가 정확히 n번 나타나는 경우를 의미한다. | |
{min,}[85][18] | 바로 앞의 요소가 최소 min번 이상 나타나는 경우를 의미한다. | |
{min,max}[85][18] | 바로 앞의 요소가 최소 min번 이상, 최대 max번 이하로 나타나는 경우를 의미한다. |
4. 문법
(''s''*는 0번 이상의 ''s''를 뜻함)]]
정규 표현식은 특정 규칙을 만족하는 텍스트 문자열을 찾기 위해 사용하는 "패턴"을 정의하는 특별한 문자열 문법이다. 정규 표현식을 구성하는 각 문자는 특별한 의미를 가진 메타문자이거나, 문자 그대로의 의미를 가진 일반 문자(리터럴 문자)이다. 예를 들어, 정규 표현식 a.에서 'a'는 문자 'a' 자체와 일치하는 리터럴 문자이고, '.'는 새줄 문자를 제외한 모든 단일 문자와 일치하는 메타 문자이다. 따라서 이 정규 표현식은 'a', 'ax', 'a0' 등과 일치할 수 있다.
메타문자와 리터럴 문자를 조합하여 원하는 텍스트 패턴을 만들 수 있다. 패턴 일치는 정확히 같은 문자열을 찾는 것부터 메타문자를 사용하여 매우 넓은 범위의 유사한 문자열을 찾는 것까지 다양하다. 예를 들어, .는 매우 포괄적인 패턴이며, [a-z]('a'부터 'z'까지의 모든 소문자 중 하나와 일치)는 덜 포괄적이고, a는 정확히 'a' 하나만 일치하는 패턴이다. 메타문자 문법은 표준 ASCII 자판으로 쉽게 입력할 수 있으면서도, 다양한 텍스트 데이터를 자동으로 처리할 수 있도록 정확하고 유연하게 패턴을 표현하기 위해 설계되었다.
정규 표현식의 간단한 예로, 문서 편집기에서 두 가지 방식으로 표기될 수 있는 단어를 찾는 경우를 들 수 있다. 예를 들어, seriali[sz]e는 "serialise"와 "serialize"를 모두 찾아낸다. 와일드카드 문자로도 비슷한 작업을 할 수 있지만, 정규 표현식은 더 다양한 메타문자를 제공하여 훨씬 복잡하고 정교한 패턴을 만들 수 있다.
주로 '''패턴'''(pattern)이라고 부르는 정규 표현식은 특정 목적에 필요한 문자열의 집합을 지정하는 데 사용된다. 문자열 집합을 지정하는 가장 간단한 방법은 원소를 하나하나 나열하는 것이지만, 정규 표현식을 사용하면 더 간결하게 표현할 수 있다. 예를 들어, "Handel", "Händel", "Haendel" 세 문자열을 포함하는 집합은 H(ä|ae?)ndel이라는 패턴으로 지정할 수 있다. 이 패턴은 세 문자열 각각과 '''일치'''(match)한다고 말한다.
정규 표현식을 구성하는 주요 연산은 다음과 같다.
; 불리언 "또는"
: 수직선 (|)은 여러 항목 중 하나를 선택하도록 구분한다. 예를 들어, gray|grey는 "gray" 또는 "grey"와 일치한다.
; 그룹 묶기
: 괄호 (())는 여러 문자를 하나의 단위로 묶거나 연산자의 적용 범위와 우선순위를 지정하는 데 사용된다. 예를 들어, gray|grey와 gr(a|e)y는 동일하게 "gray" 또는 "grey" 문자열 집합을 나타낸다.
; 양의 지정 (수량자)
: 문자나 그룹 뒤에 붙는 수량자는 해당 요소가 몇 번 반복될 수 있는지를 지정한다.
'''?''': 바로 앞의 요소가 0번 또는 1번 나타나는 경우와 일치한다. 예를 들어,colou?r는 "color"와 "colour" 모두와 일치한다.''': 바로 앞의 요소가 0번 이상 나타나는 경우와 일치한다. 예를 들어,* '''ab*c는 "ac", "abc", "abbc", "abbbc" 등과 일치한다.'''+''': 바로 앞의 요소가 1번 이상 나타나는 경우와 일치한다. 예를 들어,ab+c는 "abc", "abbc", "abbbc" 등과 일치하지만 "ac"와는 일치하지 않는다.'''{n}'''[18]: 바로 앞의 요소가 정확히 ''n''번 나타나는 경우와 일치한다.'''{min,}'''[18]: 바로 앞의 요소가 최소 ''min''번 이상 나타나는 경우와 일치한다.'''{min,max}'''[18]: 바로 앞의 요소가 최소 ''min''번 이상, 최대 ''max''번 이하로 나타나는 경우와 일치한다.
정규 표현식 패턴은 대상 문자열과 일치하는지 검사하는 데 사용된다. 패턴은 일련의 '''원자'''(atom)로 구성된다. 원자는 패턴 내에서 대상 문자열과 일치시키려는 가장 기본적인 단위이다. 가장 단순한 원자는 리터럴 문자이지만, 괄호
( )를 사용하여 패턴의 일부를 그룹화하여 하나의 원자처럼 다룰 수도 있다. 메타문자는 이러한 원자를 만들고, 원자가 몇 번 반복되는지 지정하는 수량자를 정의하고, 여러 대안 중 하나를 선택하는 논리적 OR 기능을 제공하고, 특정 원자의 부재를 나타내는 NOT 기능을 제공하며, 이전에 일치한 원자를 다시 참조하는 역참조(backreference) 기능을 가능하게 한다.정규 표현식 엔진에 따라 약 14개의 문자가 메타문자로 사용될 수 있다. 이 문자들은 상황에 따라 또는 백슬래시(
\)와 함께 사용되는 이스케이프 처리 여부에 따라 리터럴 문자로 취급될 수도, 메타문자로 취급될 수도 있다. 일반적으로 사용되는 메타문자는 {}[]()^$.|*+?와 \ 등이다.4. 1. 구분 문자
프로그래밍 언어에서 정규 표현식은 일반적으로 일반적인 문자열 리터럴로 표현되며, 따라서 따옴표로 묶인다. 이는 C, 자바, 파이썬 등에서 흔히 볼 수 있는 방식으로, 예를 들어 정규 표현식re는 "re"와 같이 문자열로 입력된다.그러나 정규 표현식을 구분 문자로 슬래시(`/`)를 사용하여 표기하는 경우도 많다. 예를 들어 정규 표현식
re를 /re/와 같이 표현하는 식이다. 이 방식은 유닉스의 초기 텍스트 편집기인 ed에서 유래했다. ed에서 /는 검색을 위한 편집기 명령어였고, /re/와 같은 표현식은 특정 패턴과 일치하는 줄들을 지정하는 데 사용되었다. 이러한 방식은 grep(global regular expression print) 명령어에서도 사용되며, grep은 대부분의 유닉스 기반 운영 체제, 예를 들어 리눅스 배포판에 포함되어 있다.유사한 규칙이 스트림 편집기인 sed에서도 사용된다. sed에서는 검색 후 치환을
s/re/replacement/ 형식으로 표현하며, /re1/,/re2/와 같이 쉼표로 패턴을 결합하여 특정 범위의 줄을 지정할 수도 있다. 이러한 슬래시 구분자 표기법은 특히 Perl 프로그래밍 언어에서 사용되면서 널리 알려졌다. Perl에서는 이 표기법이 일반 문자열 리터럴과 구별되는 독자적인 구문의 일부를 형성한다.sed나 Perl과 같은 도구에서는 슬래시 외에 다른 문자를 구분자로 사용할 수도 있다. 이는 정규 표현식 패턴 자체에 슬래시 문자가 포함될 경우, 이를 이스케이프 처리해야 하는 번거로움을 피하기 위함이다. 예를 들어, sed에서
s,/,X, 명령은 쉼표(,)를 구분자로 사용하여 슬래시(`/`) 문자를 X로 바꾸는 작업을 수행한다.4. 2. 표준
POSIX 표준은 정규 표현식에 대해 세 가지 표기법을 제시하는데, 이는 '''단순 정규 표현식''', '''기본 정규 표현식'''('''BRE''', Basic Regular Expression영어), 그리고 '''확장 정규 표현식'''('''ERE''', Extended Regular Expression영어)이다. 이 중 단순 정규 표현식은 오래된 방식으로 현재는 잘 사용되지 않으며[61][62], 하위 호환성을 위해 남아 있지만 앞으로는 없어질 수도 있다.[63] 따라서 현대적인 정규 표현식 표준은 주로 기본 정규 표현식(BRE)과 확장 정규 표현식(ERE)을 중심으로 다룬다.BRE와 ERE의 주요 차이점 중 하나는 일부 메타문자를 다루는 방식에 있다. 예를 들어, 하위 표현식을 묶는 괄호 `()`나 반복 횟수를 지정하는 중괄호 `{}`를 사용할 때, BRE에서는 이스케이프 문자 `\`를 사용하여 `\(` `\)` 와 `\{` `\}` 형태로 써야 특별한 의미를 가지지만, ERE에서는 `\` 없이 `()` 와 `{}` 를 그대로 사용하면 메타문자로 인식된다. 반대로 이 문자들을 일반 문자로 사용하려면 ERE에서는 `\`를 붙여야 한다.
또한, 정규 표현식의 기본적인 개념 중 하나인 문자 클래스는 특정 문자 집합 중 하나의 문자와 일치하도록 하는 기능이다. 예를 들어 `[A-Z]`는 모든 대문자를, `\d`는 모든 숫자를 의미할 수 있다. 그런데 `[a-z]`와 같이 범위를 지정하는 방식은 컴퓨터의 로캘 설정이나 문자 인코딩 방식에 따라 결과가 달라질 수 있다. 예를 들어, 알파벳 순서가 'abc...zABC...Z'일 수도 있고, 'aAbBcC...zZ'일 수도 있기 때문이다. 이러한 문제를 해결하고 어떤 환경에서든 일관된 결과를 얻기 위해, POSIX 표준에서는 `[:alnum:]`(영숫자), `[:alpha:]`(알파벳), `[:digit:]`(숫자) 등과 같은 표준 문자 클래스를 정의하고 있다. 이러한 POSIX 문자 클래스는 대괄호 표현식 안에서 사용된다(예: `:digit:`).
4. 2. 1. POSIX 기본 정규 표현식 (BRE)
POSIX 기본 정규 표현식(Basic Regular Expressions, '''BRE''')은 전통적인 유닉스 도구에서 사용되는 정규 표현식 문법이다. 이 문법에서는 대부분의 문자가 일반 문자로 취급되어 그 자체와 일치하지만, 특별한 의미를 가지는 메타문자가 존재한다. BRE에서 메타문자로 취급되는 것은., [, ], ^, $, * 이며, 이스케이프 문자 \ 와 함께 사용될 때 특별한 의미를 가지는 \(, \), \{, \}, 그리고 백 레퍼런스를 위한 \1부터 \9까지가 있다.[86][66][67]BRE 문법에서 메타문자
( )와 { }는 그 자체로는 일반 문자로 취급되며, 특별한 의미(하위 표현식 그룹화, 반복 횟수 지정)를 가지려면 반드시 백슬래시(\)를 앞에 붙여 \( \) 와 \{ \} 형태로 사용해야 한다. 이는 확장 정규 표현식(ERE)과의 주요 차이점 중 하나이다.아래는 POSIX BRE에서 사용되는 주요 메타문자와 그 기능이다.
| 메타문자 | 기능 | 설명 |
|---|---|---|
. | 임의의 문자 | 새줄 문자를 제외한 임의의 한 문자와 일치한다. (동작 방식은 구현에 따라 다를 수 있음) |
[ ] | 문자 클래스 | 대괄호 [ ] 사이에 있는 문자 중 하나와 일치한다. 하이픈(-)을 사용하여 범위를 지정할 수 있다 (예: [a-z], [0-9]). 대괄호 안에서 하이픈(-)을 일반 문자로 사용하려면 맨 앞이나 맨 뒤에 위치시켜야 한다 (예: [abc-], [-abc]). 닫는 대괄호(])를 포함시키려면 맨 앞에 위치시킨다 (예: []abc]). |
[^ ] | 부정 문자 클래스 | 대괄호 [ ] 사이에 없는 문자 중 하나와 일치한다. ^는 대괄호 안에서 맨 앞에 위치해야 부정의 의미를 가진다. (예: [^0-9]는 숫자가 아닌 문자와 일치) |
^ | 시작 위치 | 문자열이나 행의 시작 부분과 일치한다. |
$ | 종료 위치 | 문자열이나 행의 끝 부분과 일치한다. |
\( \) | 하위 표현식 (캡처 그룹) | 괄호 안의 표현식을 하나의 그룹으로 묶고, 일치된 부분을 나중에 참조(백 레퍼런스)할 수 있도록 캡처한다. BRE에서는 반드시 \(와 \)로 사용해야 한다. |
\n | 백 레퍼런스 | 이전에 \( \)로 캡처된 n번째 하위 표현식과 동일한 문자열과 일치한다. n은 1부터 9까지의 숫자이다.[31] 이 기능은 이론적으로 정규 언어의 범위를 벗어난다. |
* | 0회 이상 반복 | 바로 앞의 문자 또는 그룹(\( \))이 0번 이상 반복되는 것과 일치한다. (예: a*는 "", "a", "aa", ... 와 일치, \(ab\)*는 "", "ab", "abab", ... 와 일치) |
\{m,n\} | 반복 횟수 지정 | 바로 앞의 문자 또는 그룹이 최소 m번, 최대 n번 반복되는 것과 일치한다. BRE에서는 반드시 \{와 \}로 사용해야 한다. (예: a\{3,5\}는 "aaa", "aaaa", "aaaaa"와 일치) |
'''예시:'''
.at: "hat", "cat", "bat", "4at", "#at" 등 "at"로 끝나는 세 글자 문자열과 일치한다.[hc]at: "hat" 또는 "cat"과 일치한다.[^b]at: "bat"을 제외하고 "at"로 끝나는 세 글자 문자열과 일치한다.^[hc]at: 행의 시작 부분에 있는 "hat" 또는 "cat"과 일치한다.[hc]at$: 행의 끝 부분에 있는 "hat" 또는 "cat"과 일치한다.\(ab\)*c: "c", "abc", "ababc" 등과 일치한다.\(.\)\1: 연속된 두 개의 동일한 문자와 일치한다 (예: "aa", "bb", "11").
로케일 설정에 따라 문자 범위(예:
[a-z])의 동작이 달라질 수 있으므로, POSIX 표준에서는 이식성을 높이기 위해 다음과 같은 문자 클래스를 정의하고 있다. 이 클래스들은 대괄호 표현식 안에서 사용된다 (예: :digit:).[68][69]| POSIX 클래스 | 의미 | 예시 (ASCII 기준) |
|---|---|---|
:upper: | 대문자 | [A-Z] |
:lower: | 소문자 | [a-z] |
:alpha: | 알파벳 문자 (대소문자) | [A-Za-z] |
:alnum: | 알파벳 문자와 숫자 | [A-Za-z0-9] |
:digit: | 숫자 | [0-9] |
:xdigit: | 16진수 문자 | [0-9A-Fa-f] |
:punct: | 구두점 문자 | [.,!?:...] 등 |
:blank: | 공백 문자 (스페이스, 탭) | [ \t] |
:space: | 공백 문자 (스페이스, 탭, 개행 등) | [ \t\n\r\f\v] |
:cntrl: | 제어 문자 | |
:graph: | 출력 가능한 문자 (공백 제외) | [^ \t\n\r\f\v[:cntrl:]] |
:print: | 출력 가능한 문자 (공백 포함) | [^\t\n\r\f\v[:cntrl:]] |
예를 들어, :upper:]ab]는 모든 대문자 또는 'a' 또는 'b' 중 한 문자와 일치한다. 몇몇 도구에서는 POSIX 표준 외에 [:word:] (알파벳, 숫자,
4. 2. 2. POSIX 확장 정규 표현식 (ERE)
POSIX 확장 정규 표현식('''ERE''', Extended Regular Expression영어)은 전통적인 유닉스의 기본 정규 표현식(BRE) 기능을 확장한 것이다. BRE와의 주요 차이점은 일부 메타 문자의 이스케이프 방식이 변경되고, 새로운 메타 문자가 추가된 점이다.ERE에서는 BRE에서 특별한 의미를 가지기 위해 역슬래시(\\)로 이스케이프 처리해야 했던 괄호 `()`와 중괄호 `{}`를 이스케이프 없이 메타 문자로 사용한다. 즉, BRE의 `\(`와 `\)`는 ERE에서 `(`와 `)`로, BRE의 `\{`와 `\}`는 ERE에서 `{`와 `}`로 표현된다. 반대로 이 문자들을 리터럴 문자로 사용하려면 ERE에서는 `\(` , `\)` , `\{` , `\}` 와 같이 역슬래시를 사용해야 한다. 또한, BRE에서 지원했던 `\''n''` 형태의 백참조(backreference) 기능은 ERE에서 제거되었다.
ERE에 추가된 주요 메타 문자는 다음과 같다.
| 메타 문자 | 기능 | 설명 |
|---|---|---|
? | 0 또는 1회 반복 | 바로 앞의 요소가 없거나 한 번 나타나는 경우에 일치한다. 예를 들어, ab?c는 "ac" 또는 "abc"와 일치한다. |
+ | 1회 이상 반복 | 바로 앞의 요소가 한 번 이상 반복되는 경우에 일치한다. 예를 들어, ab+c는 "abc", "abbc", "abbbc" 등과 일치하지만, "ac"와는 일치하지 않는다. |
| 선택 (OR) |
'''예시:'''
[hc]?at: "at", "hat", "cat"과 일치한다. (h 또는 c가 0번 또는 1번 나타남)[hc]*at: "at", "hat", "cat", "hhat", "chat", "hcat", "cchchat" 등과 일치한다. (h 또는 c가 0번 이상 나타남)[hc]+at: "hat", "cat", "hhat", "chat", "hcat", "cchchat" 등과 일치하지만, "at"와는 일치하지 않는다. (h 또는 c가 1번 이상 나타남)cat|dog
다음 표는 기본 정규 표현식(BRE)과 확장 정규 표현식(ERE)의 주요 문법 차이를 보여준다.
예를 들어, 확장 정규 표현식 a\.(\(|\))는 문자열 "a.)" 또는 "a.("와 일치한다. 여기서 `\.`는 리터럴 마침표(.)를, `\(`와 `\)`는 리터럴 괄호를 의미하며, `|`는 선택을 나타낸다.
POSIX 확장 정규 표현식은 '''ERE'''[70]라고도 불린다. 현대의 많은 UNIX영어 유틸리티에서는 명령 줄 옵션으로 -E 플래그를 사용하여 확장 정규 표현식을 사용할 수 있다.[71]
4. 2. 3. 문자 클래스
문자 클래스는 문자열 자체를 찾는 것 다음으로 기본적인 정규 표현식 개념이다. 문자 클래스를 사용하면, 특정 문자 집합을 정의하여 해당 집합에 속하는 '''하나의 문자'''와 일치시킬 수 있다. 예를 들어, `[A-Z]`는 영어 알파벳 대문자 전체를 의미하며, `\d`는 임의의 숫자 하나를 의미할 수 있다. 문자 클래스는 POSIX 표준에서도 정의되어 있다.`[a-z]`와 같이 특정 문자 범위를 지정할 때, 컴퓨터의 로캘 설정에 따라 문자 인코딩 순서가 달라 결과가 예상과 다를 수 있다. 예를 들어, 문자 순서가 'abc...zABC...Z'일 수도 있고, 'aAbBcC...zZ'일 수도 있기 때문이다.[68] 이러한 문제를 해결하기 위해 POSIX 표준은 다양한 환경에서 일관되게 동작하는 문자 클래스를 정의하고 있다. 주요 POSIX 문자 클래스와 펄(Perl), Vim, 자바(Java) 등 다른 환경에서 사용되는 유사한 표현은 다음과 같다.[69]
주요 문자 클래스 비교
{| class="wikitable"
|-
! 설명 !! POSIX !! Perl/Tcl !! Vim !! Java !! ASCII
|-
| ASCII 문자 || || || || `\p{ASCII}` || `[\x00-\x7F]`
|-
| 영숫자 || `[:alnum:]` || || || `\p{Alnum}` || `[A-Za-z0-9]`
|-
| 영숫자 + "_" (단어 문자)[86] || `[:word:]` (비표준) || `\w` || `\w` || `\w` || `[A-Za-z0-9_]`
|-
| 비 단어 문자 || || `\W` || `\W` || `\W` || `[^A-Za-z0-9_]`
|-
| 알파벳 문자 || `[:alpha:]` || || `\a` || `\p{Alpha}` || `[A-Za-z]`
|-
| 공백과 탭 || `[:blank:]` || || `\s` || `\p{Blank}` || `[ \t]`
|-
| 단어 경계 || || `\b` || `\< \>` || `\b` || `(?<=\W)(?=\w)\|(?<=\w)(?=\W)`
|-
| 비 단어 경계 || || || || `\B` || `(?<=\W)(?=\W)\|(?<=\w)(?=\w)`
|-
| 제어 문자 || `[:cntrl:]` || || || `\p{Cntrl}` || `[\x00-\x1F\x7F]`
|-
| 숫자 || `[:digit:]` || `\d` || `\d` || `\p{Digit}` 또는 `\d` || `[0-9]`
|-
| 비 숫자 || || `\D` || `\D` || `\D` || `[^0-9]`
|-
| 보이는 문자 (그래픽) || `[:graph:]` || || || `\p{Graph}` || `[\x21-\x7E]`
|-
| 소문자 || `[:lower:]` || || `\l` || `\p{Lower}` || `[a-z]`
|-
| 보이는 문자 및 공백 (인쇄 가능) || `[:print:]` || || `\p` || `\p{Print}` || `[\x20-\x7E]`
|-
| 구두점 || `[:punct:]` || || || `\p{Punct}` || `[][!"#$%&'()*+,./:;<=>?@\^_`
| 메타 문자 | 매치 대상 | 설명 |
|---|---|---|
| `\d` | 아라비아 숫자 | `[0-9]`와 동일 |
| `\D` | 숫자가 아닌 문자 | `[^\d]` 또는 `[^0-9]`와 동일 |
| `\w` | 영숫자 문자 또는 밑줄 | 로케일 설정에 따라 포함 문자가 달라질 수 있음 (예: 움라우트 포함 여부). 기본적으로 `[a-zA-Z0-9_]`와 유사. |
| `\W` | 영숫자 문자 또는 밑줄이 아닌 문자 | `[^\w]`와 동일 |
| `\s` | 공백 문자 | ASCII|아스키eng 기준으로는 `[ \t\n\r\f]` (띄어쓰기, 탭, 개행 문자 등)와 동일 |
| `\S` | 공백 문자가 아닌 문자 | `[^\s]`와 동일 |
이처럼 강력하고 편리한 기능을 갖춘 펄의 정규 표현식은 많은 프로그래밍 언어와 도구에 큰 영향을 주었다. 펄 호환 정규 표현식(PCRE, Perl Compatible Regular Expressions) 라이브러리는 이러한 펄 정규 표현식의 기능을 다른 응용 프로그램에서도 거의 동일하게 사용할 수 있도록 개발된 범용 라이브러리이다. PCRE는 많은 최신 소프트웨어에 통합되어 널리 사용되고 있다.
5. 이용
정규 표현식은 다양한 텍스트 처리 작업과 문자열 처리에 유용하게 사용된다. 이는 처리하는 데이터가 반드시 텍스트 형태일 필요는 없다. 일반적으로 데이터 검증, 데이터 스크래핑 (특히 웹 스크래핑), 데이터 랭글링, 단순한 파싱, 문법 강조 시스템 개발 등 다양한 작업에 응용된다.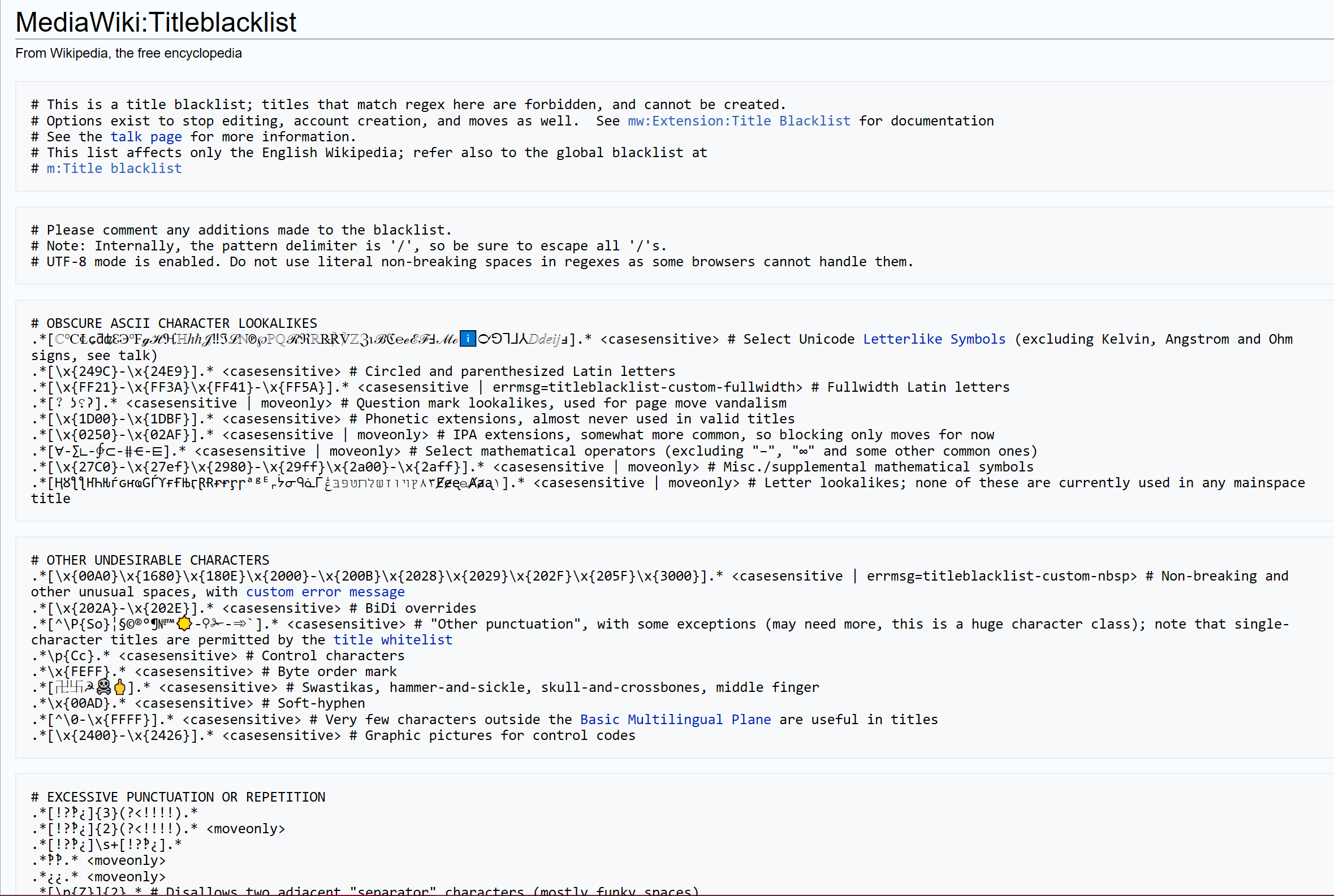
일부 고급 데스크톱 출판 소프트웨어에서는 정규 표현식을 사용하여 텍스트 스타일을 자동으로 적용하기도 한다. 예를 들어, 텍스트를 소문자 대문자로 만드는 문자 스타일을 정의하고, 정규 표현식 `'[A-Z]{4,}'`를 사용하여 해당 스타일을 적용하면, 4개 이상의 연속된 대문자로 이루어진 모든 단어가 자동으로 소문자 대문자로 표시되도록 할 수 있다. 이를 통해 레이아웃 작업자가 수동으로 스타일을 적용하는 수고를 덜 수 있다.
정규 표현식은 인터넷 검색 엔진에서도 유용하게 사용될 수 있다. 하지만 전체 데이터베이스를 대상으로 정규 표현식을 처리하는 것은 정규 표현식의 복잡성과 설계 방식에 따라 컴퓨터 자원을 과도하게 소모할 수 있다는 단점이 있다. 이 때문에 대부분의 검색 엔진은 일반 사용자에게 정규 표현식 검색 기능을 제공하지 않는다. 시스템 관리자들은 내부적으로 정규 표현식 기반의 검색을 수행할 수 있는 경우가 많지만, 일반 대중에게 이 기능을 공개하는 경우는 드물다. 과거 구글 코드 검색이나 엑스리드(Exalead)와 같은 일부 서비스에서 정규 표현식 검색을 지원하기도 했으나, 구글 코드 검색은 2012년 1월에 서비스가 종료되었다.[54]
6. 예
정규 표현식은 예제 없이 설명하고 이해하기 어려울 수 있다. 아래에는 정규 표현식의 속성 중 일부에 대한 기본적인 설명을 예시와 함께 제시한다.
아래의 항목들은 예제에 사용된다.[55][88]
- 메타문자 ;; 메타문자들의 열은 표현할 정규식을 지정한다.
- =~ m// ;; 펄에서 문자열을 '일치'시키려는 동작을 지정한다.
- =~ s/// ;; 펄에서 문자열을 '대체'시키려는 동작을 지정한다.
이 예제들에 사용된 문법과 규칙들은 다른 프로그래밍 환경에서도 유사하게 적용될 수 있다.[56][89]
| 메타문자 | 설명 | 예시[57][90] |
|---|---|---|
. | 일반적으로 줄 바꿈 문자를 제외한 모든 한 문자와 일치한다. 대괄호 [] 안에서는 문자 그대로 마침표(.)를 의미한다. | |
( ) | 패턴 요소들을 하나의 요소로 묶는다(그룹화). 괄호 안의 패턴과 일치된 부분은 나중에 $1, $2, ... 등을 사용하여 참조할 수 있다 (캡처링). 일부 구현에서는 \1, \2 등을 사용하기도 한다. | |
+ | 바로 앞의 패턴 요소가 1번 이상 반복되는 경우와 일치시킨다. | |
? | 바로 앞의 패턴 요소가 0번 또는 1번 나타나는 경우와 일치시킨다. | |
? (수량자 뒤) | *?, +?, ??, {M,N}?와 같이 수량자 뒤에 붙어, 가능한 가장 적은 횟수만큼 일치하도록 만든다 (느긋한(lazy) 또는 최소(minimal) 일치). 기본값은 탐욕적(greedy) 일치이다. | |
* | 바로 앞의 패턴 요소가 0번 이상 반복되는 경우와 일치시킨다. (클레이니 스타) | |
{M,N} | 바로 앞의 패턴 요소가 최소 M번, 최대 N번 반복되는 경우와 일치시킨다.{M}은 정확히 M번, {M,}은 최소 M번, {,N}은 최대 N번 ({0,N}과 동일) 일치를 의미한다.예: x* y+ z?는 x{0,} y{1,} z{0,1}와 같다. | |
[...] | 대괄호 안의 문자 중 하나와 일치시킨다. 문자 범위를 지정할 수도 있다 (예: [a-z], [0-9]). | |
| > | 또는(OR)을 의미하며, 여러 패턴 중 하나를 선택하여 일치시킨다. | |
\b | 단어 경계(word boundary)와 일치시킨다. 단어 경계는 단어를 구성하는 문자(\w)와 단어를 구성하지 않는 문자(\W) 사이의 위치, 또는 문자열의 시작/끝과 단어 문자 사이의 위치를 의미한다. 너비가 0인 경계(zero-width assertion)이다. | |
\w | 단어를 구성하는 문자와 일치시킨다. 보통 영문자([A-Za-z]), 숫자([0-9]), 그리고 밑줄(_)을 포함한다. 유니코드를 지원하는 환경에서는 더 많은 문자를 포함할 수 있다.[53] | |
\W | 단어를 구성하지 않는 문자와 일치시킨다 (\w의 반대). 보통 영문자, 숫자, 밑줄을 제외한 문자를 의미한다. | |
\s | 공백 문자와 일치시킨다. 보통 스페이스( ), 탭(\t), 줄 바꿈(\n, \r), 폼 피드(\f) 등을 포함한다. 유니코드 환경에서는 더 많은 공백 문자를 포함할 수 있다. | |
\S | 공백 문자가 아닌 문자와 일치시킨다 (\s의 반대). | |
\d | 숫자(digit)와 일치시킨다. 보통 [0-9]를 의미한다. 유니코드 환경에서는 다른 문자 체계의 숫자도 포함할 수 있다. | |
\D | 숫자가 아닌 문자와 일치시킨다 (\d의 반대). | |
^ | 문자열이나 줄의 시작 부분과 일치시킨다. (단, [^...]처럼 대괄호 안에서 사용될 때는 부정의 의미를 가진다.) | |
$ | 문자열이나 줄의 끝 부분과 일치시킨다. | |
\A | 문자열의 절대 시작 부분과 일치시킨다. ^와 달리, 여러 줄 모드(multiline mode)에서도 문자열의 맨 처음하고만 일치한다. | |
\z | 문자열의 절대 끝 부분과 일치시킨다.[58][91] $와 달리, 여러 줄 모드에서도 문자열의 맨 끝하고만 일치한다 (단, 마지막에 줄 바꿈 문자가 있으면 그 앞과 일치하는 경우도 있음. \Z와 구분 필요). | |
[^...] | 대괄호 안의 문자를 제외한 모든 문자와 일치시킨다 (부정 문자 클래스). |
참조
[1]
웹사이트
Regular Expression Tutorial - Learn How to Use Regular Expressions
https://www.regular-[...]
2016-10-31
[2]
서적
The Oxford Handbook of Computational Linguistics
https://books.google[...]
Oxford University Press
2003
[3]
서적
Finite Automata
https://books.google[...]
CRC Press
2003-09-17
[4]
웹사이트
How a Regex Engine Works Internally
https://www.regular-[...]
2024-02-24
[5]
웹사이트
How Do You Actually Use Regex?
https://www.howtogee[...]
2020-03-11
[6]
웹사이트
Regular Languages and Finite Automata
https://www.cs.nmsu.[...]
2010-09-16
[7]
문서
Kleene 1951, pg46
https://www.rand.org[...]
[8]
서적
Beautiful Code
O'Reilly Media
2007-08-08
[9]
웹사이트
An incomplete history of the QED Text Editor
http://cm.bell-labs.[...]
[10]
웹사이트
Jargon File 4.4.7: grep
http://catb.org/jarg[...]
2003
[11]
웹사이트
New Regular Expression Features in Tcl 8.1
http://www.tcl.tk/do[...]
[12]
웹사이트
Documentation: 9.3: Pattern Matching
http://www.postgresq[...]
[13]
웹사이트
Perl Regular Expressions
http://perldoc.perl.[...]
2006
[14]
문서
Wall
2002
[15]
웹사이트
PCRE - Perl Compatible Regular Expressions
https://www.pcre.org[...]
[16]
웹사이트
GRegex – Faster Analytics for Unstructured Text Data
https://grovf.com/pr[...]
[17]
웹사이트
CUDA grep
http://bkase.github.[...]
[18]
웹사이트
grep(1) - Linux manual page
https://man7.org/lin[...]
[19]
문서
Hopcroft
2000
[20]
문서
Sipser
1998
[21]
문서
Gelade
2008
[22]
문서
Gruber
2008
[23]
문서
Based on Gelade
2008
[24]
웹사이트
Regular expressions for deciding divisibility
https://s3.boskent.c[...]
[25]
간행물
(Title unknown)
1984
[26]
서적
Introduction to Automata Theory, Languages, and Computation
Addison Wesley
2003
[27]
문서
Kozen
1991
[28]
논문
On defining relations for the algebra of regular events
http://umj.imath.kie[...]
1964
[29]
문서
'ISO/IEC 9945-2:1993 Information technology – Portable Operating System Interface (POSIX) – Part 2: Shell and Utilities'
[30]
문서
The Single Unix Specification (Version 2)
[31]
서적
The Open Group Base Specifications Issue 7, 2018 edition
The Open Group
[32]
웹사이트
Regular Expression Matching: the Virtual Machine Approach
https://swtch.com/~r[...]
[33]
웹사이트
Perl Regular Expression Documentation
https://perldoc.perl[...]
perldoc.perl.org
[34]
웹사이트
Regular Expression Syntax
https://docs.python.[...]
Python Software Foundation
[35]
문서
SRE: Atomic Grouping (?>...) is not supported #34627
https://github.com/p[...]
[36]
웹사이트
Essential classes: Regular Expressions: Quantifiers: Differences Among Greedy, Reluctant, and Possessive Quantifiers
https://docs.oracle.[...]
Oracle
2016-12-23
[37]
웹사이트
Atomic Grouping
https://www.regular-[...]
2019-11-24
[38]
간행물
I-Regexp: An Interoperable Regular Expression Format
Internet Engineering Task Force
2024-03-11
[39]
논문
A Formal Study of Practical Regular Expressions
http://137.149.157.5[...]
2003-12
[40]
웹사이트
Perl Regular Expression Matching is NP-Hard
https://perl.plover.[...]
2019-11-21
[41]
서적
QED Text Editor
https://wayback.arch[...]
1970-06
[42]
웹사이트
How to simulate lookaheads and lookbehinds in finite state automata?
https://cs.stackexch[...]
2019-11-24
[43]
웹사이트
Perl 5: perlre.pod
https://github.com/P[...]
1994-10-18
[44]
웹사이트
Jumbo Regexp Patch Applied (with Minor Fix-Up Tweaks): Perl/perl5@c277df4
https://github.com/P[...]
1997-11-19
[45]
문서
Cox
2007
[46]
문서
Laurikari
2009
[47]
웹사이트
gnulib/lib/dfa.c
https://git.savannah[...]
2022-02-12
[48]
논문
Sublinear Matching With Finite Automata Using Reverse Suffix Scanning
2013-08
[49]
논문
NR-grep: a fast and flexible pattern-matching tool
https://users.dcc.uc[...]
2019-11-21
[50]
웹사이트
travisdowns/polyregex
https://github.com/t[...]
2019-11-21
[51]
논문
Regular Expressions with Backreferences: Polynomial-Time Matching Techniques
2019-03
[52]
웹사이트
Vim documentation: pattern
http://vimdoc.source[...]
Vimdoc.sourceforge.net
2013-09-25
[53]
웹사이트
UTS#18 on Unicode Regular Expressions, Annex A: Character Blocks
https://unicode.org/[...]
2010-02-05
[54]
웹사이트
A fall sweep
https://googleblog.b[...]
2019-05-04
[55]
Webarchive
perldoc perlre
https://web.archive.[...]
2009-12-31
[56]
문서
Java (programming language) O'Reilly Media#In a Nutshell, Python (programming language) Scripting for Computational Science, Programming PHP
[57]
문서
All the if statements return a TRUE value
[58]
서적
Perl Best Practices
O'Reilly
2017-09-10
[59]
서적
オートマトン言語理論 計算論 I 第2版
サイエンス社
[60]
서적
コンピュータとは何か?
東京電機大学出版局
[61]
문서
lang-en-short|historical
[62]
문서
lang-en-short|legacy
[63]
문서
lang-en-short|may be withdrawn
[64]
문서
lang-en-short|simple regular expressions
[65]
문서
POSIX > XSH > regexp(3)
http://pubs.opengrou[...]
[66]
문서
lang-en-short|basic regular expression
[67]
문서
POSIX > Base Definitions > Regular Expressions > Basic Regular Expressions
http://pubs.opengrou[...]
[68]
문서
これは正規表現として「[a-z]」を使用していたことが原因である。
[69]
문서
所定の文字列を内側の括弧およびコロンで囲って「POSIX クラスを表現」し、外側の括弧は「その1字のみからなる正規表現を記述」している。
[70]
문서
lang-en-short|extended regular expression
[71]
웹사이트
'POSIX > Base Definitions > Regular Expressions > Extended Regular Expressions'
http://pubs.opengrou[...]
[72]
웹사이트
PCRE - Perl Compatible Regular Expressions
http://www.pcre.org/
[73]
Github
https://github.com/kkos/oniguruma
https://github.com/k[...]
[74]
Github
https://github.com/k-takata/Onigmo
https://github.com/k[...]
[75]
웹사이트
Perl Regular Expression Syntax - 1.81.0
https://www.boost.or[...]
[76]
웹사이트
syntax_option_type Synopsis - 1.81.0
https://www.boost.or[...]
[77]
웹사이트
'
[78]
웹사이트
'Regular expressions library (since C++11) - cppreference.com'
https://en.cpprefere[...]
[79]
웹사이트
正規表現ライブラリ - cppreference.com
https://ja.cpprefere[...]
[80]
웹사이트
regex - cpprefjp C++日本語リファレンス
https://cpprefjp.git[...]
[81]
웹사이트
What Regular Expressions Are Exactly - Terminology
http://www.regular-e[...]
[82]
서적
The Oxford Handbook of Computational Linguistics
https://books.google[...]
Oxford University Press
[83]
서적
Finite Automata
https://books.google[...]
CRC Press
2003-09-17
[84]
웹인용
Regular Languages and Finite Automata
https://www.cs.nmsu.[...]
New Mexico State University
2019-08-13
[85]
문서
grep(1) man page
[86]
서적
한 권으로 끝내는 정규표현식
한빛미디어(주)
[87]
웹인용
Perl Regular Expression Documentation
http://perldoc.perl.[...]
perldoc.perl.org
2012-01-08
[88]
문서
[89]
문서
[90]
문서
모든 if문은 true(참)을 반환한다
[91]
서적
Perl Best Practices
http://www.scribd.co[...]
O'Reilly
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com